Apache Pulsar Functions
Apache Pulsar Functions
Apache Pulsar Functions
Apache Pulsar functions process simple tasks. Pulsar functions do not completely remove the need for separate technologies such as Apache Heron, Apache Storm, or Apache Flink, for complicated processing. However, often processing logic or computation is simple enough for it to be handled natively using Pulsar functions.
Handling the computations natively within Pulsar preserves operational simplicity by not requiring additional technology for processing.
These computations can be broken into three steps.
- First, a message is consumed from one or more Pulsar topics.
- Then, a user-supplied processing logic or computation is applied to the message.
- Finally, the results of the processing are applied to another topic to be read by subscribed consumers.
Example Pulsar Function
The figure below shows an example of how Pulsar Functions can be used.
Here we are pulling in text from restaurant reviews. The Pulsar function is a word counter, likely to be used later for machine learning / natural language processing.
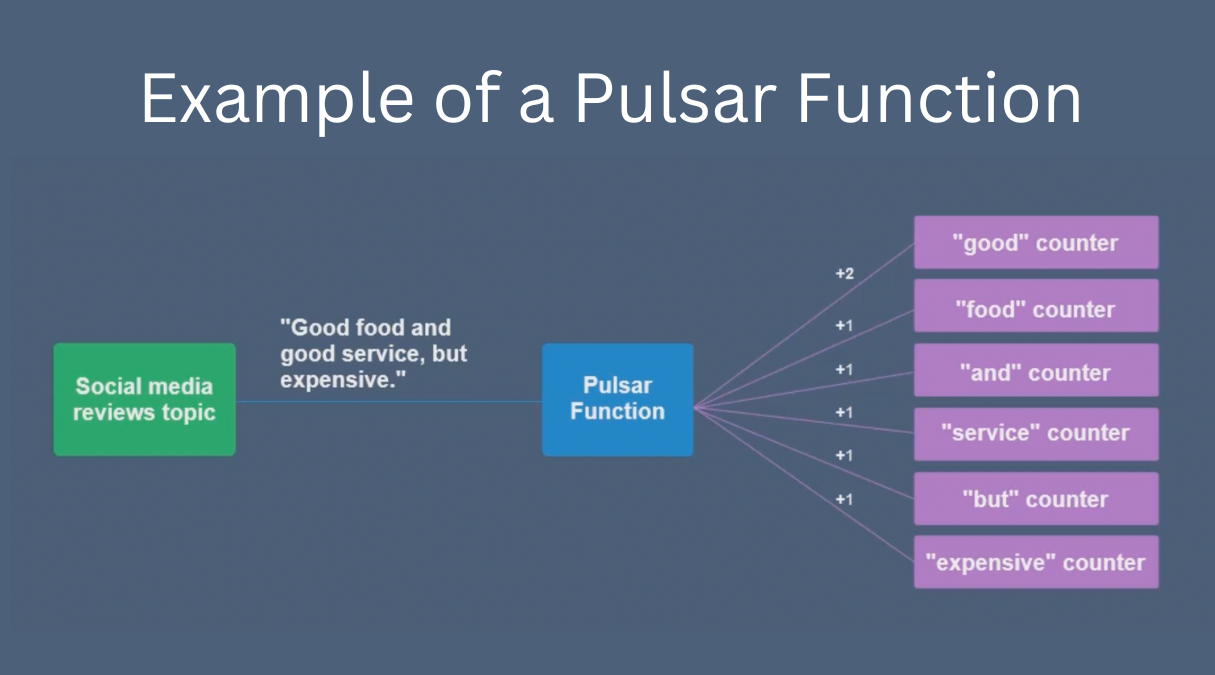
First, the text will be sent to a Pulsar topic. Then, the text will be processed through the word counter. And finally, the processed result will be sent to a new topic.
Applications can then subscribe to the topic that collects the processed data.
More information can be found in the documentation page for Pulsar functions. Or reach out to us for support with your Pulsar clusters.
24x7 Pulsar Support & Consulting
24x7 Pulsar Support & Consulting
24x7 Pulsar Support & Consulting
Visit our Apache Pulsar™ page for more details on our support services.