Structure Basics for Kafka and RabbitMQ
Both Kafka and RabbitMQ bridge two traditional messaging technologies: shared message queue and publish-subscribe. In brief, in the shared message queue model individual messages are sent to the queue by a producer and read only once by a single consumer. In the publish-subscribe model (also referred to as pub/sub), the senders (publishers) and receivers (subscribers) of messages are decoupled. Subscribers receive messages only from the topics to which they are explicitly subscribed. Check out this post for a detailed background on these two traditional messaging models and how Kafka works.
The term topic is used for publish-subscribe implementations, referring to consumers subscribing to messages published to particular topics. There are two types of subscriptions, ephemeral and durable. Both types can be employed when using Kafka or RabbitMQ; however the specific terms ephemeral and durable are more often used when discussing RabbitMQ rather than Kafka:
A. Ephemeral subscription: Subscriptions to topics that are active only within the limit that the consumer is active/running. When the consumer stops running, then the subscription and any unprocessed messages are lost.
B. Durable subscription: Subscriptions to topics are maintained until they are specifically deleted. The subscription is maintained even if a consumer shuts down. When the consumer is running again, the message processing is resumed.
Apache Kafka
Kafka is ideal for handling large amounts of homogeneous messages, such as logs or metric, and it is the right choice for instances with high throughput.
Kafka’s use of consumer groups make it ideal for scaling event streaming. Kafka uses the pub/sub model but changes terminology to producers and consumers, respectively. Just as with the pub/sub model, producers and consumers are decoupled, and consumers subscribe to topics, or more specifically partitions within topics. Here is a post that goes into more detail on Kafka architecture.
Kafka consumers can either be subscribed to topics via an ephemeral or durable subscription. With an ephemeral subscription the consumer group offset restarts from the most recent record in each partition whenever a consumer shuts down and then restarts. Durable subscriptions in Kafka allow consumers to maintain their consumer group offset even if the consumer shuts downs and restarts.
Benefits of Kafka
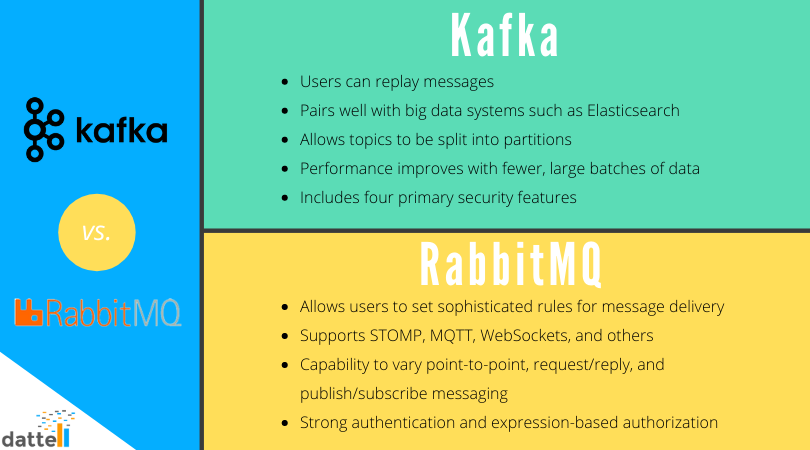
![]() Replay Messages. One of the key highlights of Kafka is that it allows the user to replay messages. This is especially important for analytical use cases. For instance, if you are tracking device data for internet of things (IoT) sensors and discover an issue with your database not storing all data, then you can replay data to replace the missing information in the database.
Replay Messages. One of the key highlights of Kafka is that it allows the user to replay messages. This is especially important for analytical use cases. For instance, if you are tracking device data for internet of things (IoT) sensors and discover an issue with your database not storing all data, then you can replay data to replace the missing information in the database.
Big Data Consideration. Kafka also pairs well with big data systems such a Elasticsearch and Hadoop. We serve clients across industries and with a range of throughputs that are best suited to a Kafka message broker and high capacity backend. The two programs work well together for scalable data collection and storage. Click here for more information on Kafka support services.
Scaling Capability. Kafka allows topics to be split into partitions. This feature is important because it allows multiple consumers to handle a portion of the stream and makes horizontal scaling possible.
Batches. Kafka works best when messages are batched. In other words, its performance improves with fewer, larger batches of data, rather than receiving lots of small messages. We recommend the smallest batch be 100 bytes, but preferably 1-10 kilobytes in size. Larger batch sizes come with a small latency increase depending on your implementation, typically a few milliseconds.
Security. Earlier versions of Kafka did not include built-in security features, but that changed with Apache Kafka 0.9. Version 0.9 includes four primary security features. 1) Administrators have the ability to require client authentication through either Transport Layer Security (TLS) or Kerberos. 2) Administrators can use a Unix-like permissions system to control user access to data. 3) Messages can be securely sent across networks with encryption. 4) Administrators can now require authentication for communication between Kafka brokers and ZooKeeper.
Mature Platform. Kafka has a large and active community with countless articles and resources available on websites like this one. There are also dozens of plugins available for distributions & packaging, stream processing, Hadoop integration, database integration, search & query, management consoles, AWS integration, logging, metrics, and more.
Drawbacks to Kafka
Kafka doesn’t come prepacked with a friendly graphical user interface. However, it is possible to create one using Kibana. See our post on monitoring Kafka for examples of what Kafka monitoring looks like with Kibana.
Comparing RabbitMQ to Kafka
Compared to Kafka, RabbitMQ can be a good choice for instances with lower throughput. RabbitMQ is slower than Kafka but provides an optimal REST API as well as an approachable graphic user interface (GUI) for monitoring queues.
RabbitMQ uses message exchanges along with the publish-subscribe messaging model. Similar to Kafka, with RabbitMQ publishers and subscribers are decoupled. Publishers publish messages to message exchanges, and consumers subscribe to the message exchanges. Also like Kafka, RabbitMQ supports both durable and ephemeral subscriptions.
Apache Cassandra is often used alongside RabbitMQ when administrators want access to stream history.
Benefits of RabbitMQ
Discrete Messaging. RabbitMQ allows users to set sophisticated rules for message delivery. Options include security and conditional routing, among others.
Multiprotocol Support. RabbitMQ was originally built as an AMQP broker, and it also supports STOMP, MQTT, WebSockets, and others.
Flexibility. RabbitMQ offers the capability to vary point-to-point, request / reply, and publish / subscribe messaging. It also allows for complex routing to consumers.
Security. RabbitMQ has a history of strong authentication and expression-based authorization.
Communication. RabbitMQ supports both synchronous and asynchronous communication.
Mature platform. RabbitMQ has a large community and there are countless articles and resources. It is available for Java, client libraries, .NET, Ruby, node.js, and has dozens of associated plugins.
Drawbacks of RabbitMQ
RabbitMQ is slower than Kafka so for high throughput use cases it will likely not be the best fit.
Comparing Redis to Kafka
Redis is another message broker option . Being in-memory only, Redis is faster than even Kafka. It works best for customers whose destination can receive data far faster than the data can be generated.
. Being in-memory only, Redis is faster than even Kafka. It works best for customers whose destination can receive data far faster than the data can be generated.
—
When to Use RabbitMQ vs Kafka
To summarize, if you’re looking for a message broker to handle high throughput and provide access to stream history, Kafka is the likely the better choice. If you have complex routing needs and want a built-in GUI to monitor the broker, then RabbitMQ might be best for your application.
Dattell’s engineers specialize in data architecture, including the design, implementation, and support of messages brokers. Reach out to us with any unanswered questions or unique use cases.